The difference between encoding, hashing, encryption and signing

I have run hundreds of phone/system design interviews, hired dozens of software engineers, and worked with them for years.
One of my best predictors of success is whether candidates knew:
- what they were talking about
- the limits of their knowledge
A bad engineer would pretend to know everything and bombard me with terms they don't understand. A good engineer would know what they don't know, and be open and honest about it.
In system design interviews, the vast majority of candidates would mention two of the terms below at one point or another. Inevitably, I would follow up towards the end of the interview: "Earlier, you mentioned X and Y. Could you please explain the difference?". Then, I would ask about the other terms.
Candidates that answered well tended to be quite strong technically. And almost all of them did very well on the job.
Is it a good interview question?
I don't like asking theoretical interview questions. Instead, I try to keep them as close as possible to what candidates would do on the job. So, is this a good interview question? I think so, because these terms pop up everywhere.
Working on security? You need to know the difference between encryption and signing. Working on caching? Hashing is your friend. Transferring some data? Encoding + encryption. Web 3? Hashing.
So if a software engineer does not understand these terms, it means they did not bother googling them. They chose ignorance. All day, every day.
Of course, this is a bit dramatic. Some engineers would not answer well, and they would still get hired. Usually because they showed some very good technical knowledge in other parts of the interview, and were good cultural fits. I blame their bad answers on their tiredness. Anecdotally, I can't remember any of those engineers misusing the terms on the job after answering the question incorrectly...
The definitions below are superficial and the bare minimum I would expect a candidate to answer to show a good grasp of the concepts.
Encoding
Encoding is the process of transforming data into another format to make it easier to consume by different systems or transfer over the network.
Encoding algorithms are reversible. It means that anybody with the encoded data and the algorithm could easily get back the original data.
Example 1: Base 64
The base 64 encoding algorithm is used to transform binary data into ASCII text using only the characters a to z, A to Z, + and / (and = for padding). It is commonly used to embed binary data into HTML or to transfer email attachments. Base 64 encoding increases the size of the data by at least 33% (24 bits are encoded using 32 bits).
Example 2: Gzip
Gzip is an encoding algorithm used to compress and decompress files. It is used in conjunction with tar to archive files, or by web servers to save bandwidth. In fact, this article was probably gzipped on its way to you.
Note that gzip can only be seen as an encoding algorithm because it's lossless. According to our definition, a lossy compression algorithm such as jpeg would not be an encoding.
Hashing
Hashing is a one-way process that transforms data into another fixed-length value, usually represented textually by a hexadecimal string.

Due to its properties, hashing is non-reversible. It is technically possible to try to find the original data or create collision, but it is unfeasible in practice for modern hashing algorithms as it would require too much computing power (6500 CPU years and 100 GPU years for SHA1).
Example 1: PBKDF2
PBKDF2 is a key derivation function used for password hashing. It is intentionally slow to avoid brute-force attacks (and to store passwords securely, a unique salt should be used to avoid rainbow table attacks).
Example 2: md5
MD5 is a hashing algorithm widely used to check for file integrity because of its speed.
Note that algorithms such as MD5 and SHA1 are susceptible to different kinds of attacks. Whenever possible, use a secure hash algorithm instead. When in doubt, ask a security professional.
Encryption
Encryption is the process of transforming data into something that only authorized users can understand. Its main purpose is confidentiality.

Encryption can be:
- Symmetric: the same key is used to encrypt and decrypt the data.
- Asymmetric: a public key is used to encrypt the data, and a private key is used to decrypt it. Public and private keys are linked by a complex mathematical relationship: the public key is easy to derive from the private key, but the private key is computationally extremely costly to guess from the public key.
Like hashing, getting back the original data from the transformed data is impossible in practice.
Example: AES 256
AES 256, Advanced Encryption Standard with 256 bits keys, is a symmetric encryption algorithm used for wireless security, file encryption, or to secure VPNs.
Signing
Signing is the process of creating a digital signature to prove the authenticity of a message. The signature does not replace the data; it is transmitted alongside it.

Like hashing, signing can be used to ensure data integrity. However, signing requires a public/private key pair, so data signed using different private keys will create different signatures. These signatures can then be used to verify the identity of the author.
A misunderstood example: JWT
I often hear that JSON Web Tokens (JWT) are encrypted. This is incorrect.
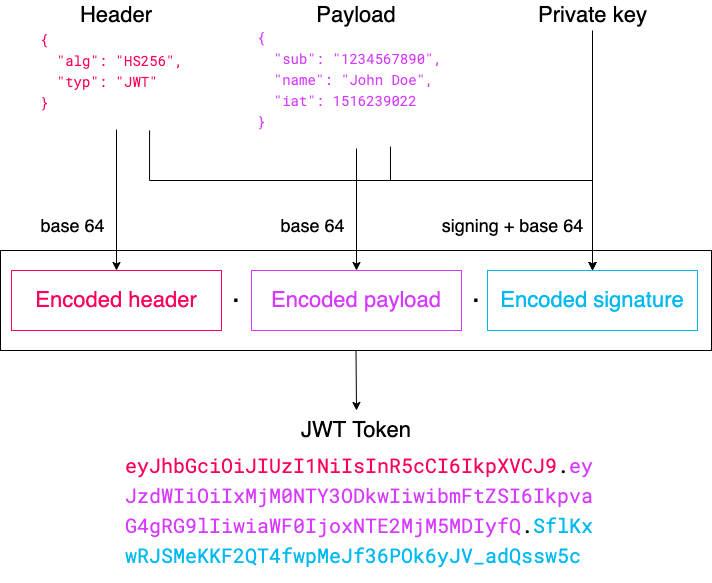
JWT tokens contain three parts:
- The header contains the type of token and the signing algorithm
- The payload contains the data carried by the token
- The signature is used to verify the authenticity of the token
Each part is represented by a base 64 encoded JSON object. The payload is not encrypted. The user receiving the token can therefore easily inspect its content (for example, using the jwt.io debugger).